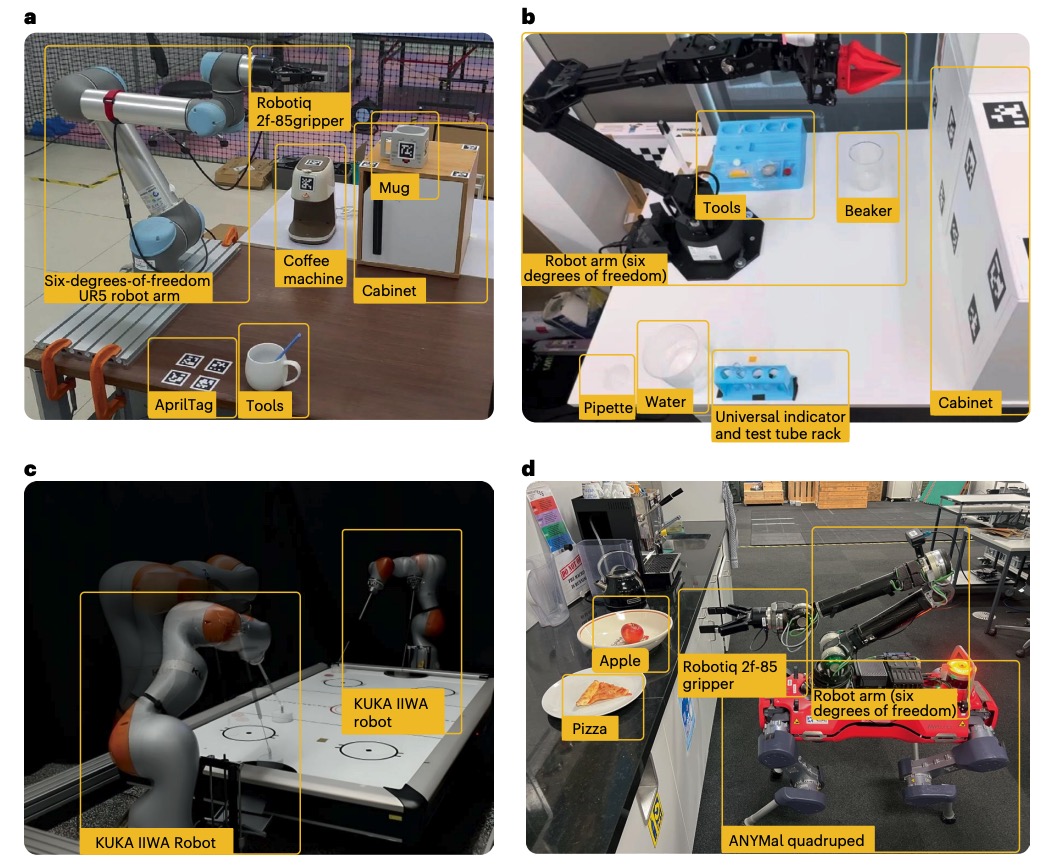
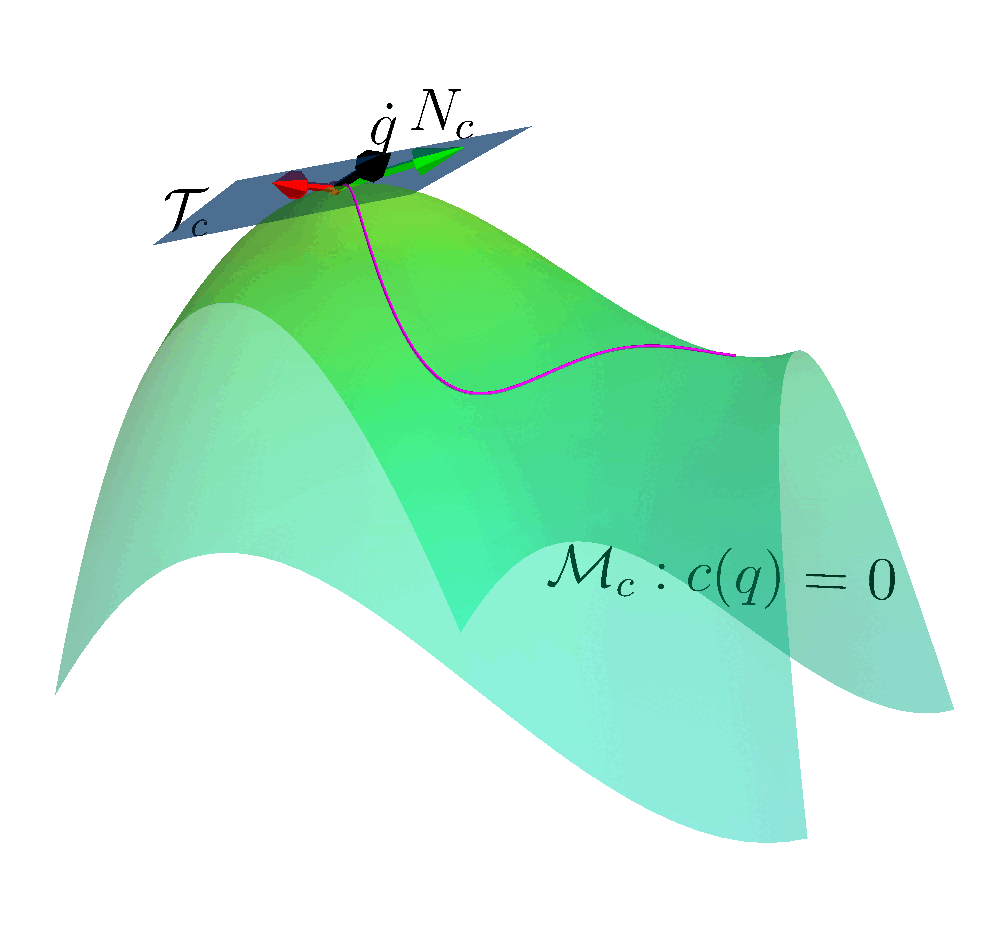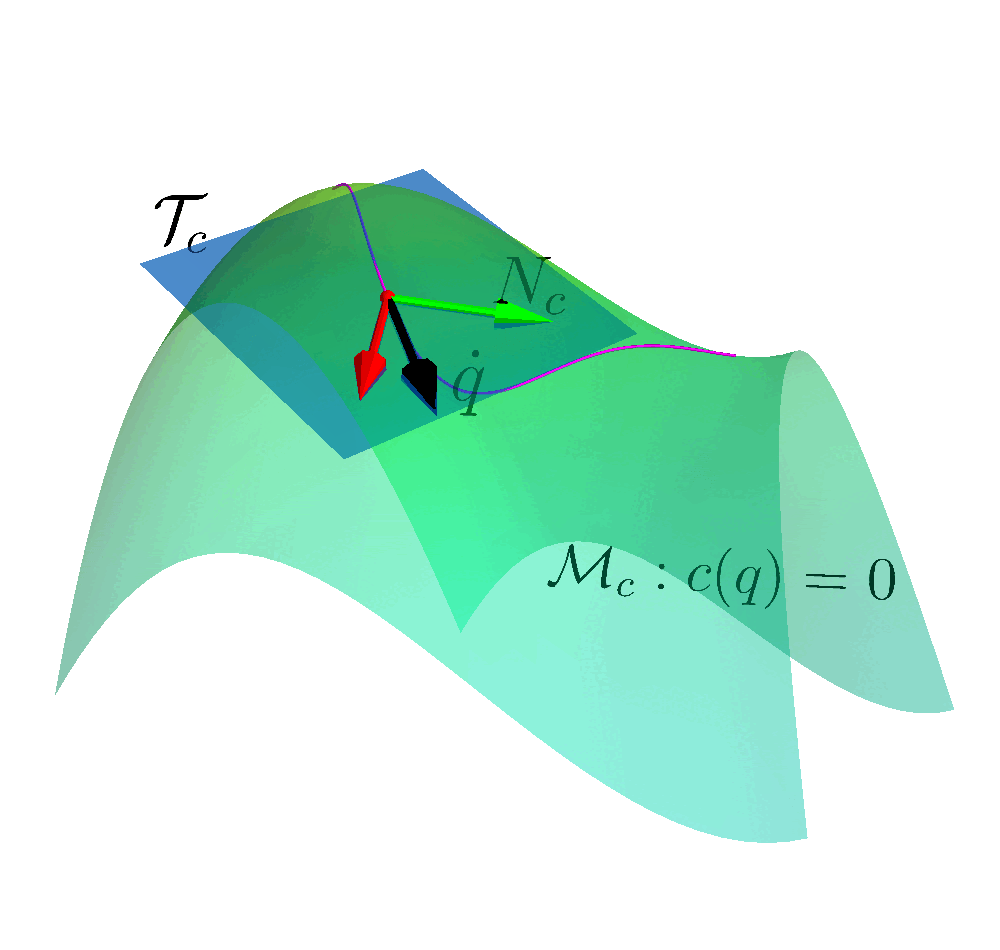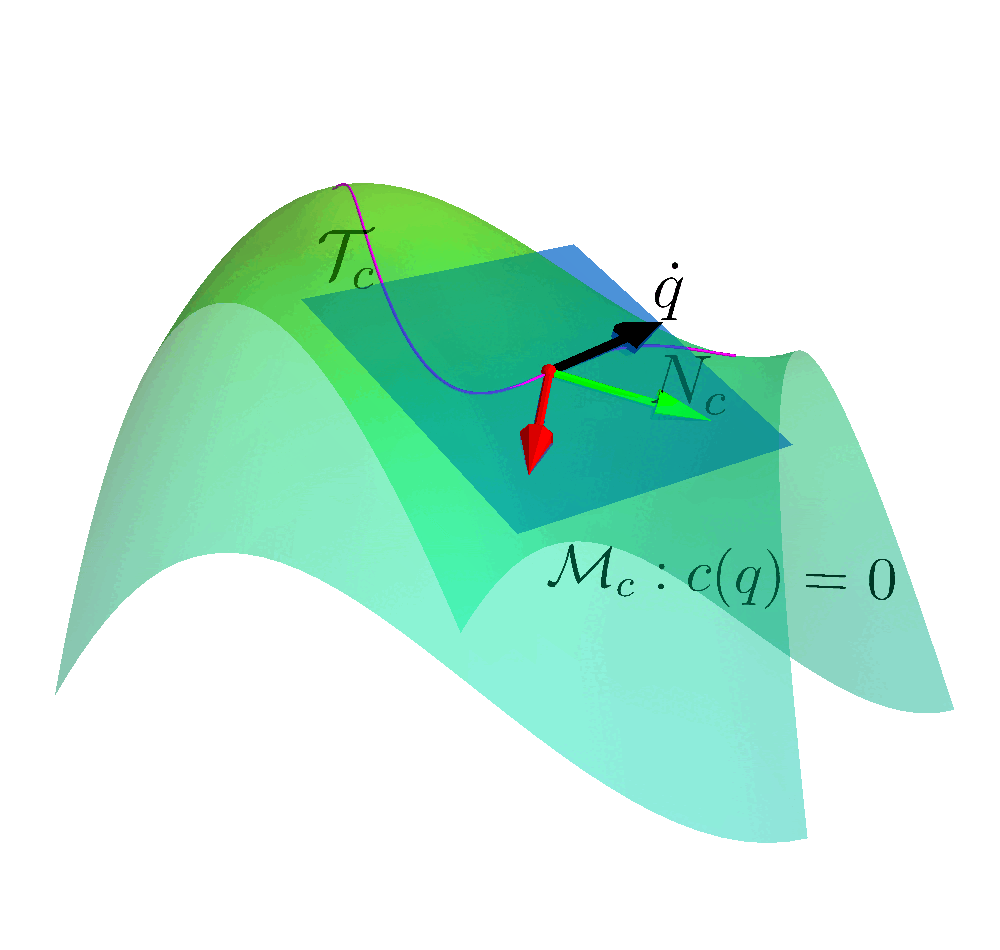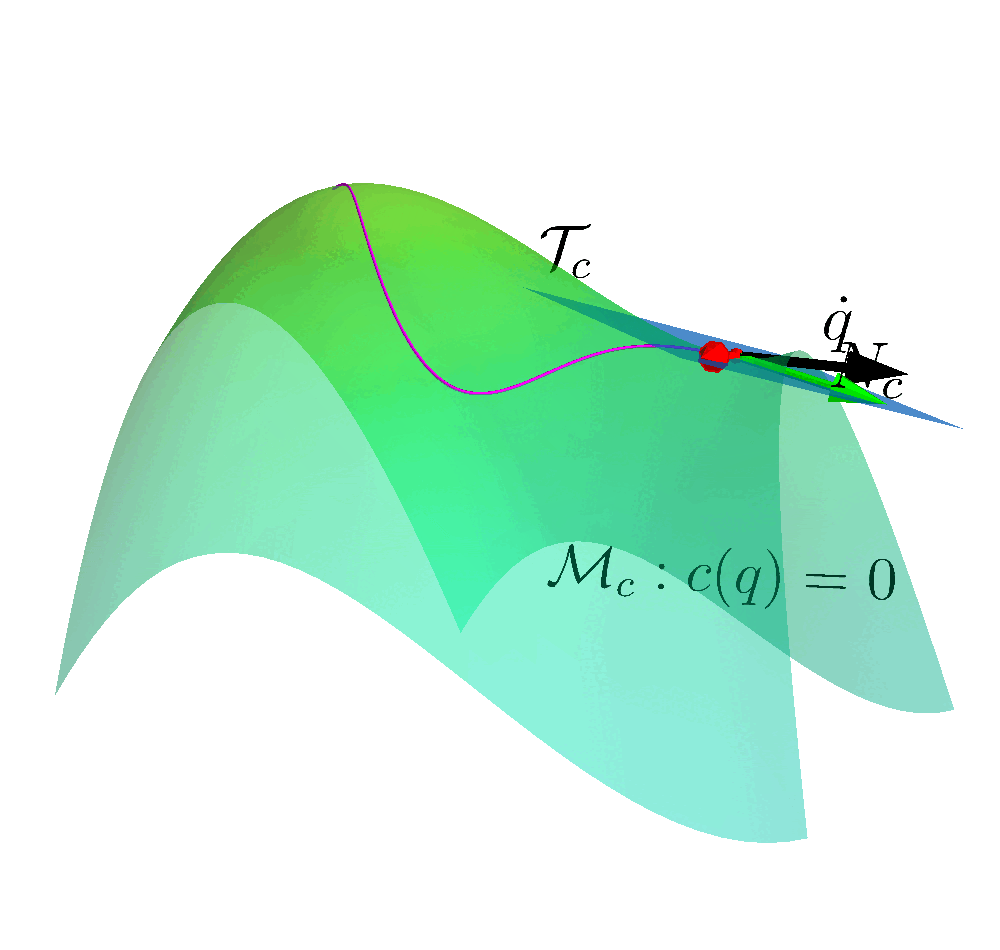A robot operating system framework for using large language models in embodied AI
Christopher E. Mower, Yuhui Wan, Hongzhan Yu, Antoine Grosnit, Jonas Gonzalez-Billandon, Matthieu Zimmer,
Puze Liu, Daniel Palenicek, Davide Tateo, Jan Peters, Kaixian Qu, Mike Zhang, Guowei Lan, Andrei Cramariuc, Cesar Cadena, Marco Hutter, Guangjian Tian, Yuzhen Zhuang, Kun Shao, Xingyue Quan, Jianye Hao, Jun Wang, and Haitham Bou-Ammar
Nature Machine Intelligence, vol. 8, pp. 313–325, Mar, 2026
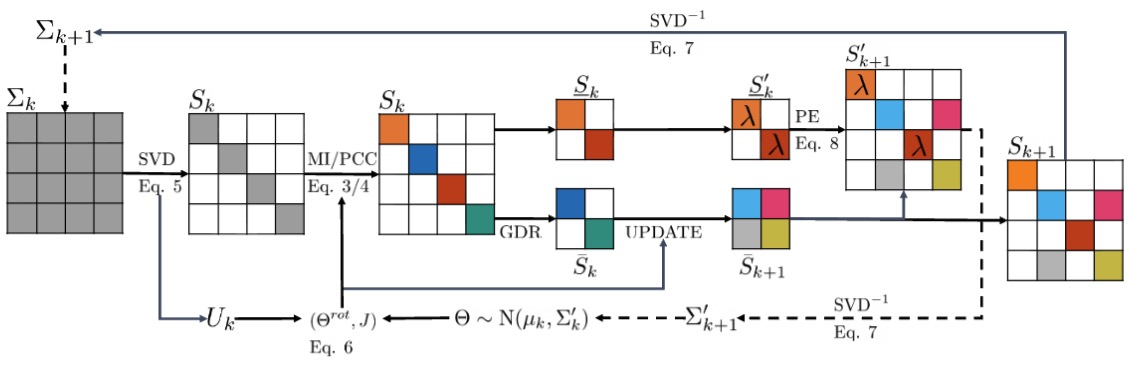
Autonomous robots capable of turning natural-language instructions into reliable physical actions remain a central challenge in artificial intelligence. Here we show that connecting a large language model agent to the robot operating system enables a versatile framework for embodied intelligence, and we release the complete implementation as freely available open-source code. The agent automatically translates large language model outputs into robot actions, supports interchangeable execution modes (inline code or behaviour trees), learns new atomic skills via imitation, and continually refines them through automated optimization and reflection from human or environmental feedback. Extensive experiments validate the framework, showcasing robustness, scalability and versatility in diverse scenarios and embodiments, including long-horizon tasks, tabletop rearrangements, dynamic task optimization and remote supervisory control. Moreover, all the results presented in this work were achieved by utilizing open-source pretrained large language models.



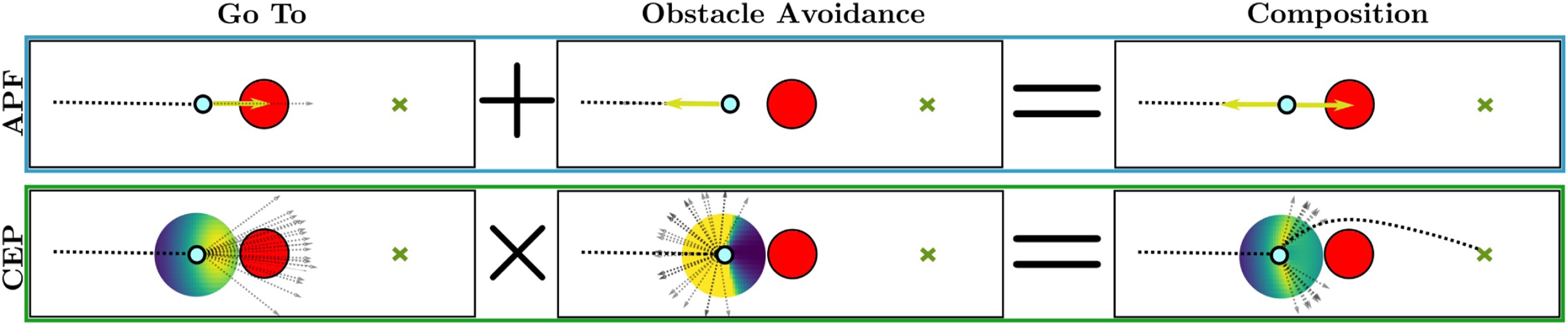

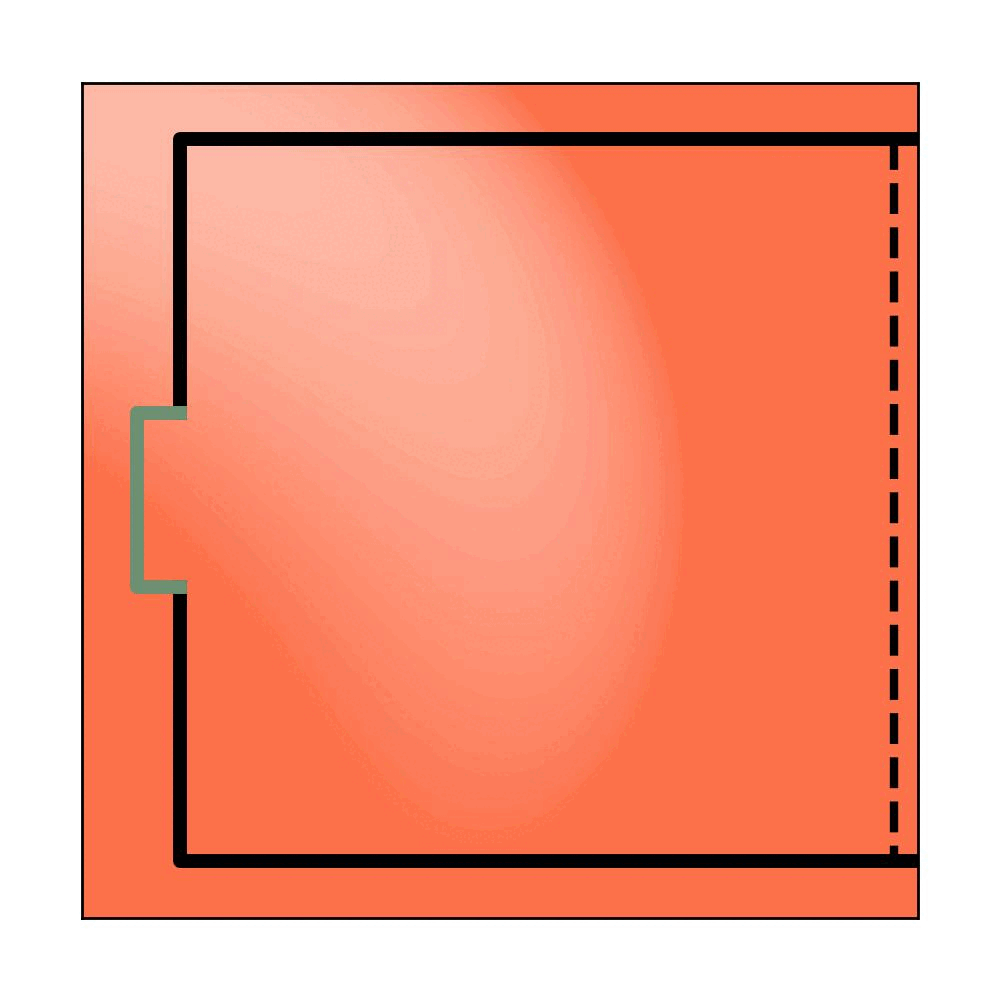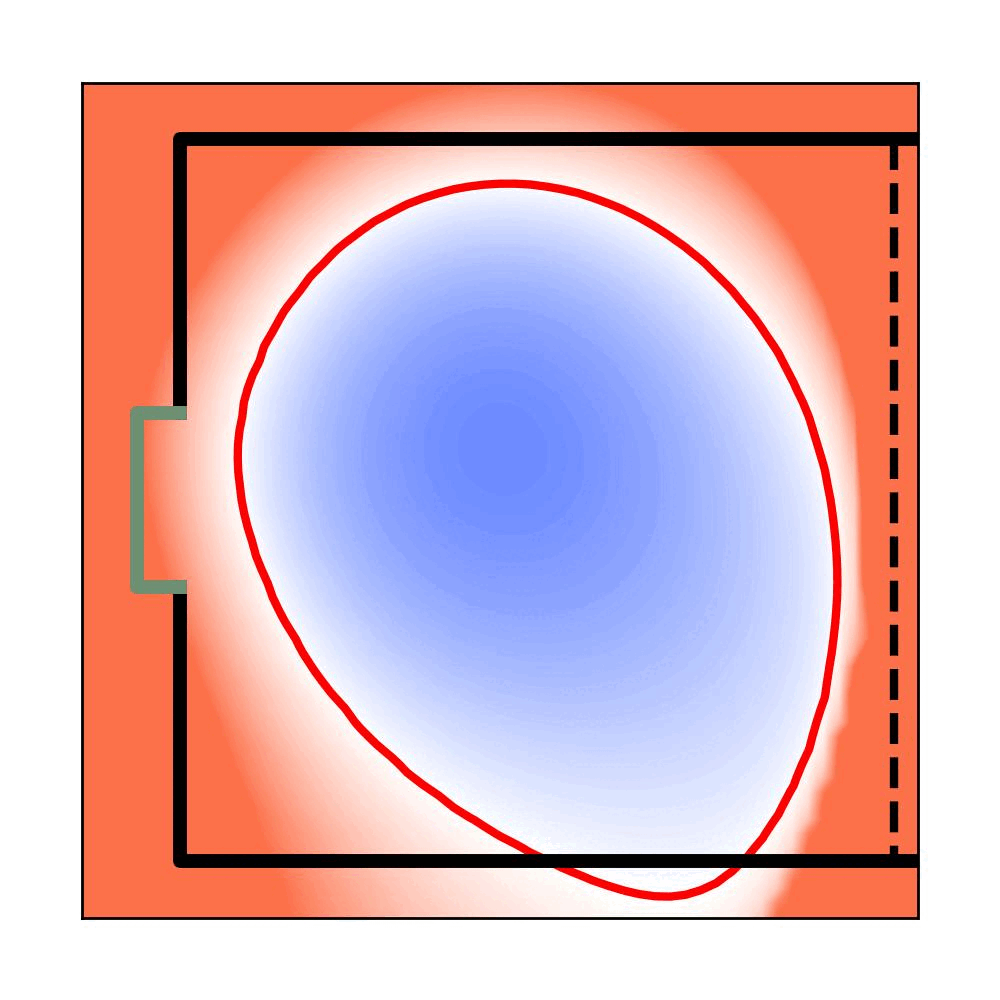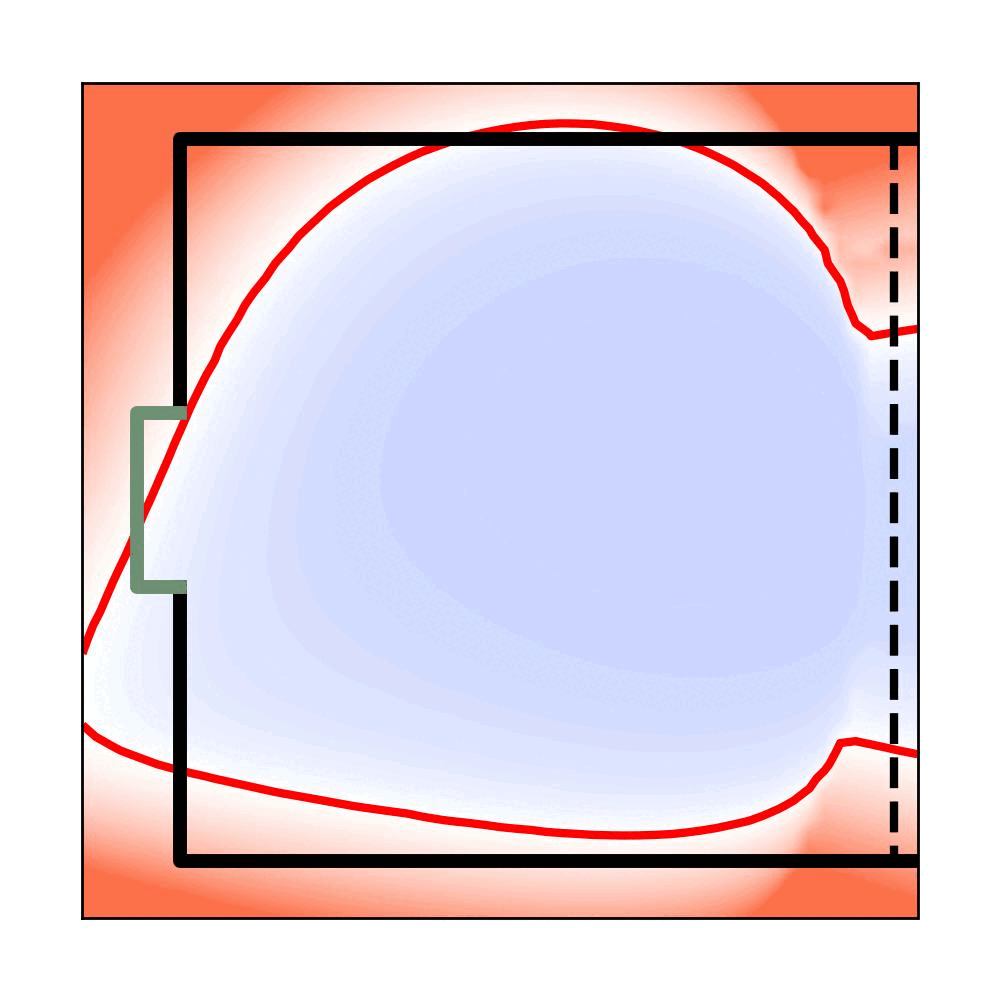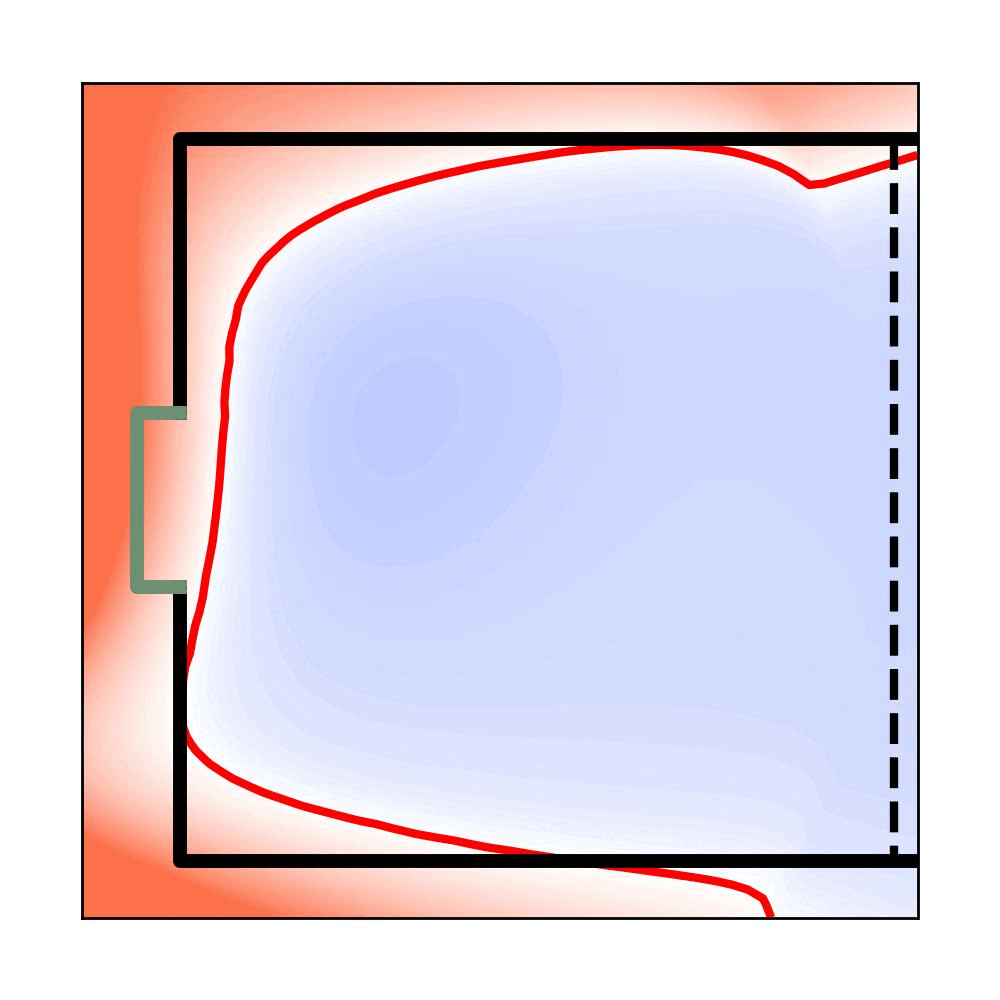 Handling Long-Term Safety and Uncertainty in Safe Reinforcement LearningIn 8th Annual Conference on Robot Learning, 2024[PDF]
Handling Long-Term Safety and Uncertainty in Safe Reinforcement LearningIn 8th Annual Conference on Robot Learning, 2024[PDF]